
Innovating Calibration of Data-Driven Models without Traditional Data

Project Overview:
In the realm of machine learning, the reliance on extensive datasets for model training is a well-known prerequisite. Typically, the complexity of a model is directly proportional to the volume of data it requires. In industrial settings, acquiring or generating substantial calibration or training data, such as specific chemical compositions, can be both challenging and expensive. Our project aimed to circumvent this obstacle by substituting these laborious measurements with more accessible spectroscopic data, combined with chemometric techniques.
Innovative Solution:
Our strategy was twofold:
1. Sparse Target Data Utilization with Process Model Integration:
We began by conducting minimal target data measurements for calibration, which would usually be insufficient. By integrating these sparse data points with a comprehensive process model, we were able to bridge the data gaps effectively. This method significantly reduced the need for costly measurements, although it had its limitations.
2. Exclusive Reliance on Spectroscopic Data and Process Knowledge:
The more radical approach involved completely foregoing traditional calibration measurements. Instead, we leveraged existing spectroscopic data variability and process knowledge for model calibration. With this setup, we could acquire spectral data frequently and inexpensively, at no additional cost. Through iterative model-based optimization, we trained various regression models, assuming the spectral data encompassed all necessary information, which was typically the case when the appropriate spectroscopic method was selected.
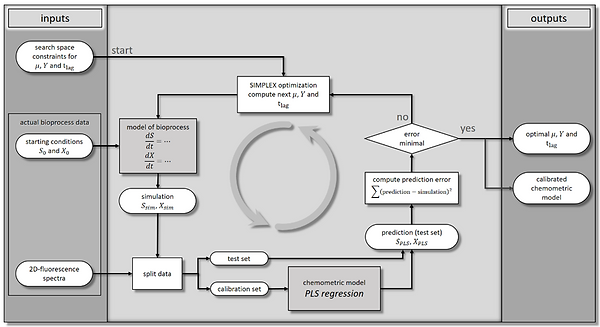
Results:
Our innovative approach yielded remarkable outcomes. We successfully trained a neural network to predict glucose, ethanol, and biomass levels in yeast fermentation solely from 2D Fluorescence spectra, without any offline measurements. The spectral data alone sufficed for model calibration. The accuracy of our model was notable, with glucose and ethanol predictions deviating by approximately 0.3 g/L, and biomass predictions by about 0.1 g/L. This demonstrates the potential of recalibrating data-driven models in resource-efficient ways without compromising on accuracy or reliability.
More Articles





Chemometrics
Process Analytical Technology
Process Analytical Technology
Process Analytical Technology
Process Analytical Technology
Innovative Meat Quality Analysis Using Hyperspectral Fluorescence Measurements
Integrated Sensor Technology for Enhanced Ethanol Monitoring.
AI-Powered Food Fraud Detection with NIR Spectroscopy
Mammalian Cell Culture Monitoring with Raman Spectroscopy
Advanced Yeast Preculture Method for Alcoholic Beverage Production
Ready to explore how our innovative solutions can benefit your business?
Contact us today to discuss how we can tailor our expertise to meet your specific needs.